5月20日,由深度学习技术与应用国家工程研究中心主办、飞桨承办的WAVE SUMMIT 2022深度学习开发者峰会线上举行。百度业界首发的文心·行业大模型成为峰会一大亮点。
联合国网、浦发首发行业大模型,开启大模型进化新格局
文心·行业大模型的核心特色是“行业知识增强”,基于通用数据训练的文心大模型,加上挖掘行业应用场景中,大量存在的行业特色大数据和知识,进一步提升大模型对行业应用的适配性。在能源、金融领域,百度与国家电网、浦发银行联合研发了行业大模型。
能源电力行业,百度和国网研发了国网-百度·文心大模型。基于通用文心大模型,在海量数据中挖掘了电力行业数据,百度与国网专家们一起,引入电力业务积累的样本数据和特有知识,并且在训练中,结合双方在预训练算法和电力领域业务与算法的经验,设计电力领域实体判别、电力领域文档判别等算法作为预训练任务,让文心大模型深入学习电力专业知识,在国网场景任务应用效果提升。
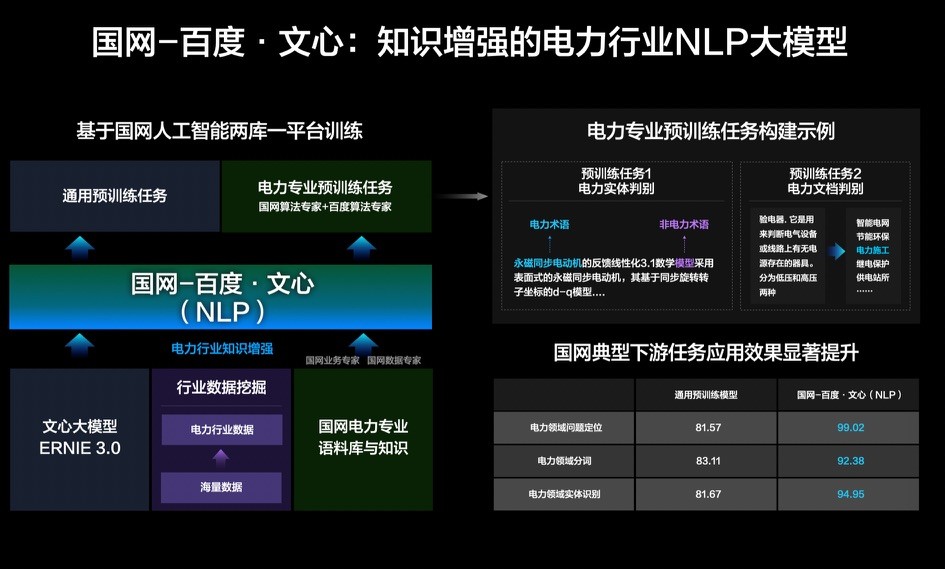
国家电网有限公司数字化工作部人工智能工作负责人蒋炜博士表示,作为中央企业数字化转型的排头兵,国家电网联合百度共同打造行业级人工智能基础设施,探索研发电力人工智能联合大模型。不仅提升了传统电力专用模型的精度,而且大幅降低了研发门槛,实现了算力、数据、技术等资源的统筹优化。下一步,国家电网公司将继续深化双方技术合作,推动人工智能大模型在电力领域的技术攻关及应用探索,面向更典型的电力业务场景,构建更具电力特色的人工智能大模型。
相似的思路,在金融领域,百度和浦发研发了浦发-百度·文心大模型。基于通用文心大模型挖掘金融行业数据,结合浦发场景积累的行业数据与知识,双方技术和业务专家一起设计了针对性的财报领域判别、金融客服问答匹配等预训练任务,让文心大模型学习到金融行业的知识,在浦发典型任务应用效果显著提升。

上海浦东发展银行总行信息科技部副总经理万化提到,浦发银行与百度在AI的多个方面实现优势互补,联合研发了面向金融行业的大模型「浦发-百度·文心」,并且已在金融行业各类智能场景进行验证。未来,浦发银行将与百度继续深入合作,在现有金融行业大模型的基础上不断迭代,持续地降低金融AI应用落地的门槛。
国家电网和浦发银行是各自领域的头部力量,对所处行业的业务知识及技术理解十分深入,百度则在AI领域深耕十余年,不断探索人工智能的创新应用。行业大模型也并非是把AI技术和行业场景的简单叠加,而是需要强强联合研发,探索方法与机制,共推大模型在行业中深度应用。这不是百度第一次与外部联合研发大模型,此前,百度联合鹏城实验室打造了全球首个知识增强千亿大模型鹏城-百度·文心,参数规模达2600亿,在机器阅读理解、文本分类、语义相似度计算等60多项任务取得最好效果,并在30余项小样本和零样本任务上刷新基准。
百度首发行业大模型,探索出一套行之有效的大模型产业落地打法,让大模型“能用、可用”,规模化落地价值显现。
提出支撑大模型产业落地三个关键路径,飞桨全面支撑大模型规模化生产和产业级应用
百度引领大模型在行业的深度应用,这与文心大模型的整体构想和顶层设计密不可分。
峰会上,百度集团副总裁、深度学习技术及应用国家工程研究中心副主任吴甜指出,文心大模型的两大特色是“产业级”和“知识增强”。她表示,“今年是大模型产业落地的关键年,要做好落地,需解决的关键问题是,前沿的大模型技术如何与真实场景的方方面面要求相匹配。“

吴甜针对这个问题清晰地给出大模型产业落地三个关键路径:
一是要建设更适配应用场景的模型体系,包含学习了足够多数据与知识的基础大模型,面向常见AI任务专门学习的任务大模型,以及首发的、引入行业特色数据和知识的行业大模型。这次百度一口气发布了10个大模型,刷新文心全景图,模型体系格局显现。
二是提供更有效的工具和方法,充分考虑落地应用的全流程问题。发布大模型开发套件、API和内置了文心大模型能力的EasyDL和BML开发平台,全方位降低应用门槛降低应用门槛,端到端、全方位发挥文心大模型效能。
三是打造开放的生态,以生态促创新。文心大模型不紧与飞桨共享生态,还新发布了基于文心大模型的创意社区——旸谷大模型创意与探索社区,让用户零距离感受文心大模型的魅力和应用创新潜力,并提供最新大模型API试用。
这三大关键路径并驾齐驱,剑指产业落地。可以说,文心大模型来源于产业实践,服务于产业实践,在实践中建设、发展、壮大。

文心大模型是深度学习平台飞桨产业级模型库中的重要一员,飞桨训练推理一体化技术,全面支撑着文心大模型规模化生产和产业级应用。
众所周知,训练大模型的挑战主要来自于“大”, 模型参数规模巨大,且不同模型和算力平台特性的差异,都是大模型训练中的现实挑战。飞桨解决了大模型训练过程中的多个世界性难题,4D并行混合训练技术以及端到端自适应分布式训练框架,为大模型的训练过程保驾护航,使大模型训练速度大幅提升,模型效果更优。
相比训练环节而言,大模型推理部署则面临更大的挑战,主要是解决算力消耗问题。对应用的企业和开发者来说,需采取蒸馏、裁剪等模型小型化的技术,最后使大模型以合适的体量进行部署使用。这也是实现大模型产业应用落地的关键所在。在大模型落地部署层面,飞桨推出了针对大模型的压缩、推理、服务化全流程部署方案,帮助大模型更好落地。
文心大模型正通过飞桨开源开放平台、百度智能云等赋能到工业、能源、金融、通信、媒体、教育等各行各业。大模型的规模化落地应用,飞桨平台的不断降低门槛,也印证着百度CTO王海峰所言:“人工智能越来越普惠,正在赋能千行百业,惠及千家万户。”





© | Copyright 环球资讯网 All Rights Reserved 版权所有 复制必究 编辑QQ: 2510129368

